Теоретически (на бумаге) мы можем все это расположить в одной таблице, например, так:
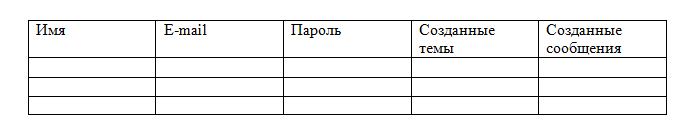
Но это противоречит свойству атомарности (одно значение в одной ячейке), а в столбцах Темы и Сообщения у нас предполагается неограниченное количество значений. Значит, нашу таблицу надо разбить на три: Пользователи, Темы и Сообщения.
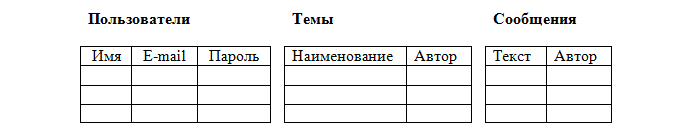
Наша таблица Пользователи удовлетворяет всем условиям. А вот таблицы Темы и Сообщения - нет. Ведь в таблице не может быть двух одинаковых строк, а где гарантия, что один пользователь не оставит два одинаковых сообщения, например:

Кроме того, мы знаем, что каждое сообщение обязательно относится к какой-либо теме. А как это можно узнать из наших таблиц? Никак. Для решения этих проблем, в реляционных базах данных существуют ключи.
Первичный ключ (сокращенно РК - primary key) - столбец, значения которого во всех строках различны. Первичные ключи могут быть логическими (естественными) и суррогатными (искусственными). Так, для нашей таблицы Пользователи первичным ключом может стать столбец e-mail (ведь теоретически не может быть двух пользователей с одинаковым e-mail). На практике лучше использовать суррогатные ключи, т.к. их применение позволяет абстрагировать ключи от реальных данных. Кроме того, первичные ключи менять нельзя, а что если у пользователя сменится e-mail?
Суррогатный ключ представляет собой дополнительное поле в базе данных. Как правило, это порядковый номер записи (хотя вы можете задавать их на свое усмотрение, контролируя, чтобы они были уникальны). Давайте внесем поля первичных ключей в наши таблицы:



Теперь каждая запись в наших таблицах уникальна. Нам осталось установить соответствие между темами и сообщениями в них. Делается это также при помощи первичных ключей. В таблицу сообщения мы добавим еще одно поле:

Теперь понятно, что сообщение с id=2 принадлежит теме "О рыбалке" (id темы = 4), созданной Васей, а остальные сообщения принадлежать теме "О рыбалке" (id темы = 1), созданной Кириллом. Такое поле называется внешний ключ (сокращенно FK - foreign key). Каждое значение этого поля соответствует какому-либо первичному ключу из таблицы "Темы". Так устанавливается однозначное соответствие между сообщениями и темами, к которым они относятся.
Последний нюанс. Предположим, у нас добавился новый пользователь, и зовут его тоже Вася:

Как мы узнаем, какой именно Вася оставил сообщения? Для этого поля автор в таблицах "Темы" и "Сообщения" мы сделаем также внешними ключами:


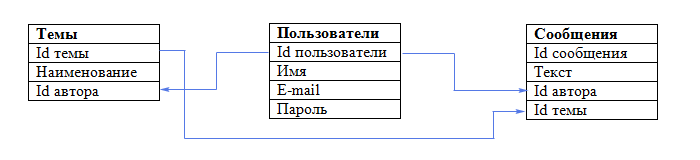
Наша база данных готова. Схематично ее можно представить так:
В нашей маленькой базе данных всего три таблички, а если бы их было 10 или 100? Понятно, что сразу невозможно представить все таблицы, поля и связи, которые нам могут понадобиться. Именно поэтому проектирование базы данных начинается с ее концептуальной модели, которую мы и рассмотрим в следующем уроке.
Предыдущий урок Вернуться в раздел Следующий урок
Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.
Главная → Основы баз данных → Урок 3. Реляционные базы данных
Базы данных - Урок 3. Реляционные базы данных
Реляционные базы данных, как мы уже знаем, состоят из таблиц. Каждая таблица состоит из столбцов (их называют полями или атрибутами) и строк (их называют записями или кортежами). Таблицы в реляционных базах данных обладают рядом свойств. Основными являются следующие:- В таблице не может быть двух одинаковых строк. В математике таблицы, обладающие таким свойством, называют отношениями - по-английски relation, отсюда и название - реляционные.
- Столбцы располагаются в определенном порядке, который создается при создании таблицы. В таблице может не быть ни одной строки, но обязательно должен быть хотя бы один столбец.
- У каждого столбца есть уникальное имя (в пределах таблицы), и все значения в одном столбце имеют один тип (число, текст, дата...).
- На пересечении каждого столбца и строки может находиться только атомарное значение (одно значение, не состоящее из группы значений). Таблицы, удовлетворяющие этому условию, называют нормализованными.
Теоретически (на бумаге) мы можем все это расположить в одной таблице, например, так:
Но это противоречит свойству атомарности (одно значение в одной ячейке), а в столбцах Темы и Сообщения у нас предполагается неограниченное количество значений. Значит, нашу таблицу надо разбить на три: Пользователи, Темы и Сообщения.
Наша таблица Пользователи удовлетворяет всем условиям. А вот таблицы Темы и Сообщения - нет. Ведь в таблице не может быть двух одинаковых строк, а где гарантия, что один пользователь не оставит два одинаковых сообщения, например:
Кроме того, мы знаем, что каждое сообщение обязательно относится к какой-либо теме. А как это можно узнать из наших таблиц? Никак. Для решения этих проблем, в реляционных базах данных существуют ключи.
Первичный ключ (сокращенно РК - primary key) - столбец, значения которого во всех строках различны. Первичные ключи могут быть логическими (естественными) и суррогатными (искусственными). Так, для нашей таблицы Пользователи первичным ключом может стать столбец e-mail (ведь теоретически не может быть двух пользователей с одинаковым e-mail). На практике лучше использовать суррогатные ключи, т.к. их применение позволяет абстрагировать ключи от реальных данных. Кроме того, первичные ключи менять нельзя, а что если у пользователя сменится e-mail?
Суррогатный ключ представляет собой дополнительное поле в базе данных. Как правило, это порядковый номер записи (хотя вы можете задавать их на свое усмотрение, контролируя, чтобы они были уникальны). Давайте внесем поля первичных ключей в наши таблицы:
Теперь каждая запись в наших таблицах уникальна. Нам осталось установить соответствие между темами и сообщениями в них. Делается это также при помощи первичных ключей. В таблицу сообщения мы добавим еще одно поле:
Теперь понятно, что сообщение с id=2 принадлежит теме "О рыбалке" (id темы = 4), созданной Васей, а остальные сообщения принадлежать теме "О рыбалке" (id темы = 1), созданной Кириллом. Такое поле называется внешний ключ (сокращенно FK - foreign key). Каждое значение этого поля соответствует какому-либо первичному ключу из таблицы "Темы". Так устанавливается однозначное соответствие между сообщениями и темами, к которым они относятся.
Последний нюанс. Предположим, у нас добавился новый пользователь, и зовут его тоже Вася:
Как мы узнаем, какой именно Вася оставил сообщения? Для этого поля автор в таблицах "Темы" и "Сообщения" мы сделаем также внешними ключами:
Наша база данных готова. Схематично ее можно представить так:
В нашей маленькой базе данных всего три таблички, а если бы их было 10 или 100? Понятно, что сразу невозможно представить все таблицы, поля и связи, которые нам могут понадобиться. Именно поэтому проектирование базы данных начинается с ее концептуальной модели, которую мы и рассмотрим в следующем уроке.
Предыдущий урок Вернуться в раздел Следующий урок
 |
Теперь нажмите кнопку, что бы не забыть адрес и вернуться к нам снова.